背景
一张表的数据越来越多 (6.5 亿 +), column 数量也越来越多
DB 版本
- Mysql 5.7
- 阿里云 Cassandra 3.11.13
迁移步骤
- 开启双写:先写 Mysql,再写 Cassandra,但以写入 Mysql 结果为准
- 同步:用脚本批量的把Mysql已有的数据同步到 Cassandra
- 同步数据完成后,把所有读改成从 Cassandra 去读数据 (灰度)
- 读接口迁移完成后,更改双写顺序,先写 Cassandra,再写 Mysql,但以写入 Cassandra 结果为准
- 观察一段时间后,下掉写 Mysql
灰度逻辑:多租户的 SaaS 系统,根据企业 ID 做灰度
双写逻辑
- Create: 同步写入 Cassandra
- Update: 查询 Cassandra 里是否已有数据,如果有则更新,没有则创建
- Delete: 查询 Cassandra 里是否已有数据,如果有则删除,没有则不用处理
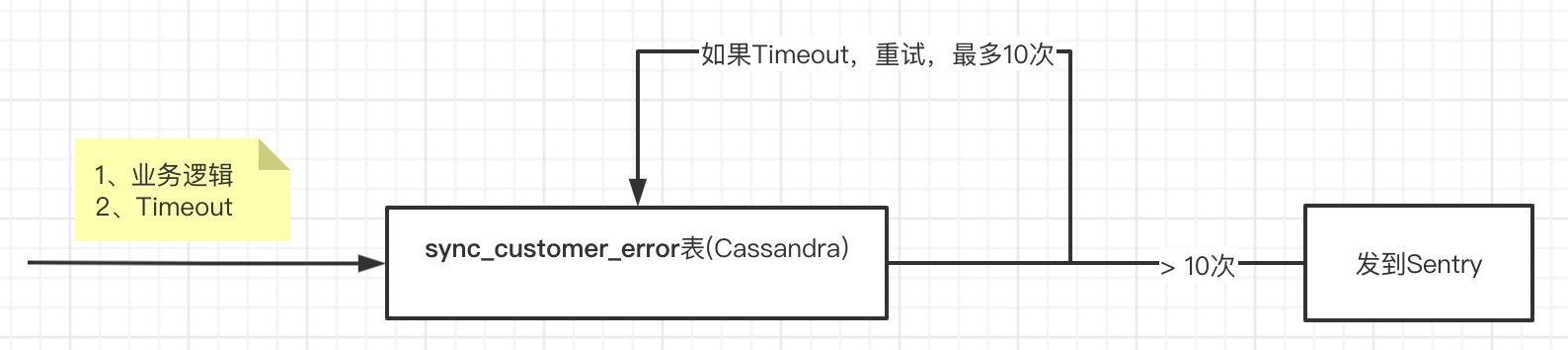
如果对 Cassandra 的操作出错了,需要记录 error,但不 break 业务逻辑,因为如果不记录 error,就会造成此次数据更新的丢失。 实际操作中,Cassandra 主要错误是:gocql: no response received from Cassandra within timeout period, 迁移的 Cassandra 配置不高,还用了耗性能的CAS,就出现了很多的 timeout。 为了方便,存 error 还是用的 Cassandra,但以防 timeout 加了 10 次的重试,如果 10 次后还失败,就会把 error 发到 sentry
同步逻辑
从 Mysql 批量读取数据,格式化成写入 Cassandra 的数据
注意点:
- 因为可能会有一些没考虑到的 panic 错误,或者需要优化同步速度不得不手动杀掉同步脚本,所以还需要存下当前的同步进度,下次跑脚本可以从上次的进度继续跑
- 从 Mysql 读取数据到内存,再到写入 Cassandra,中间这一段时间会存在并发的双写,为了避免写入过期的数据而造成数据丢失,所以同步脚本的写入需要使用
INSERT ... IF NOT EXISTS
方案
v1
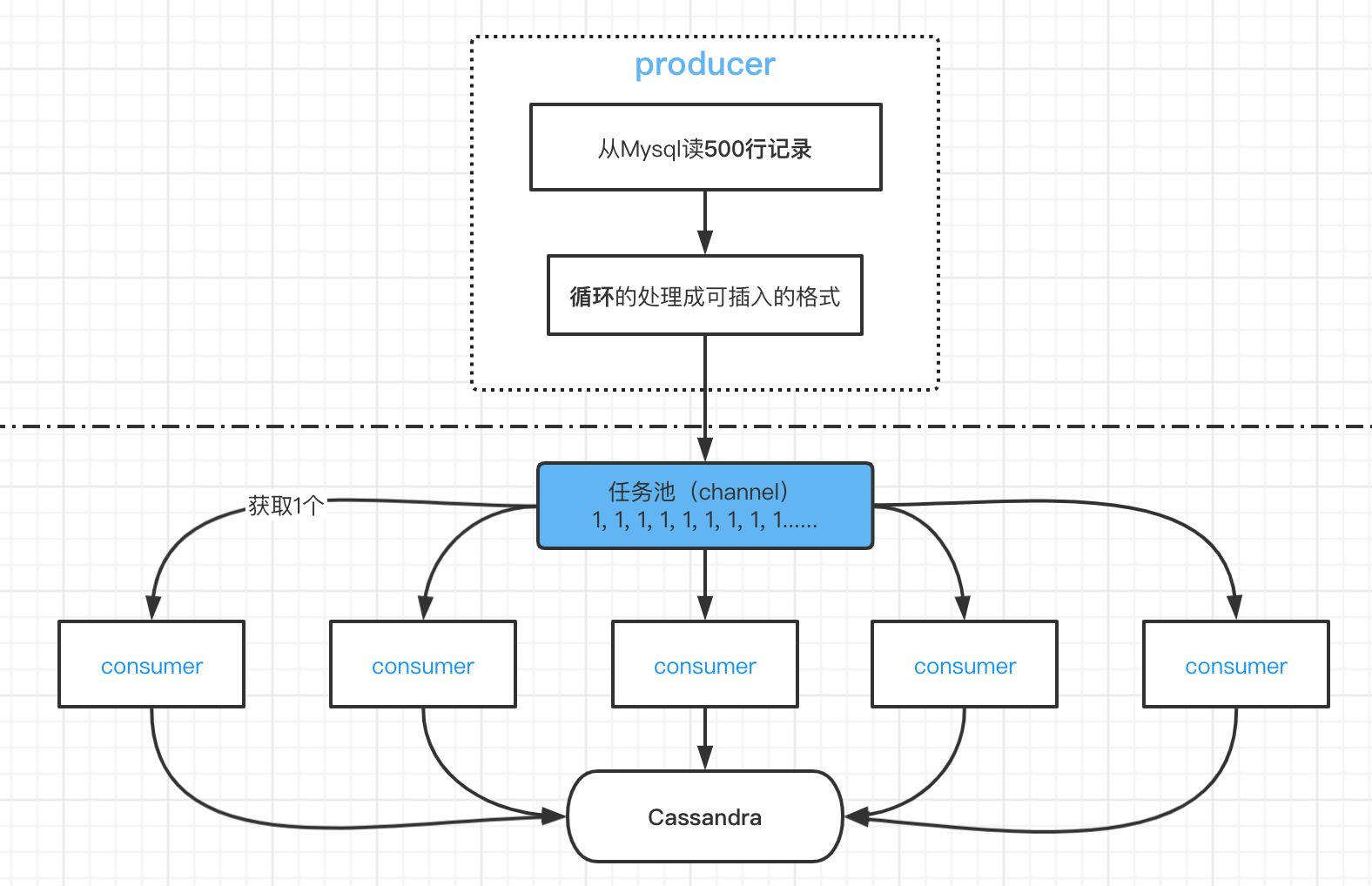
1:5 的生产者 - 消费者模型,1 个 producer 每次从 Mysql 中读取 500 条数据,放到 channel 里被消费,跑了部分数据,估算了一下,跑完需要 50 多天
展示当前迁移速度与进度
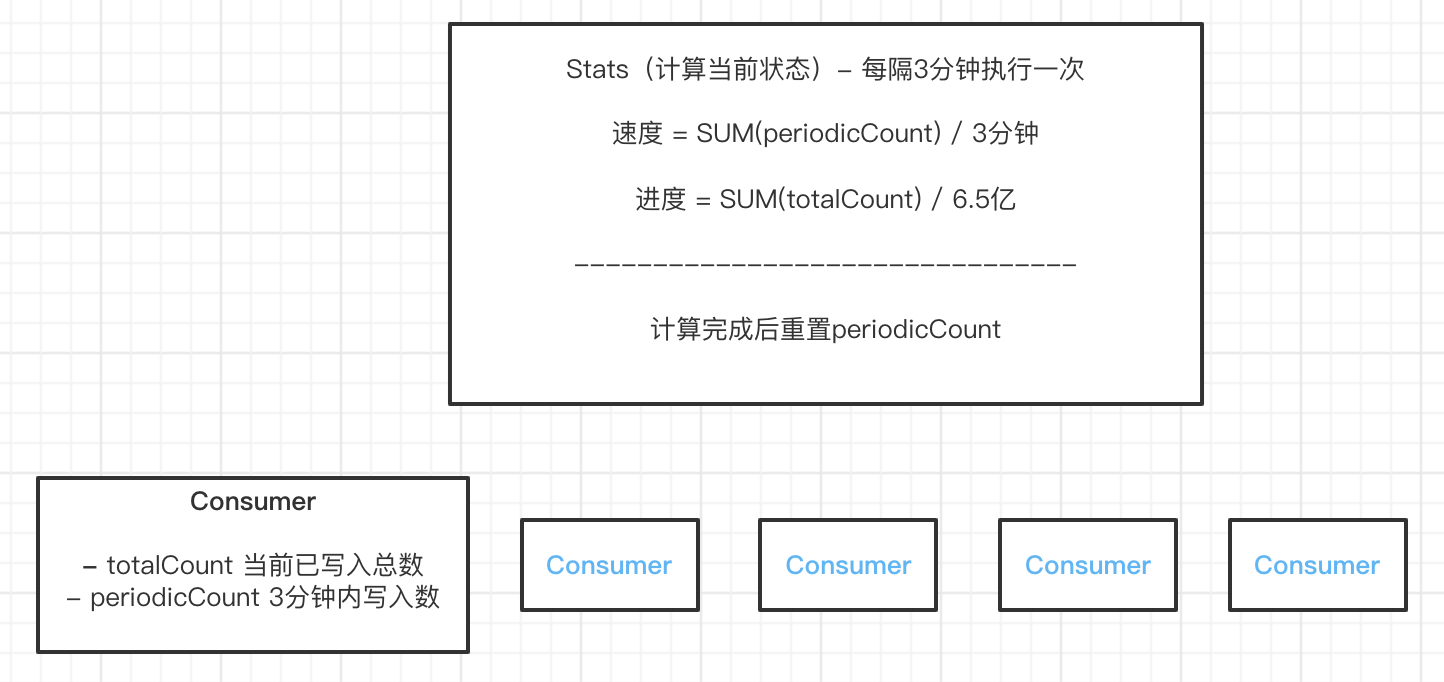
所有变量通过使用sync/atomic确保并发安全
v2
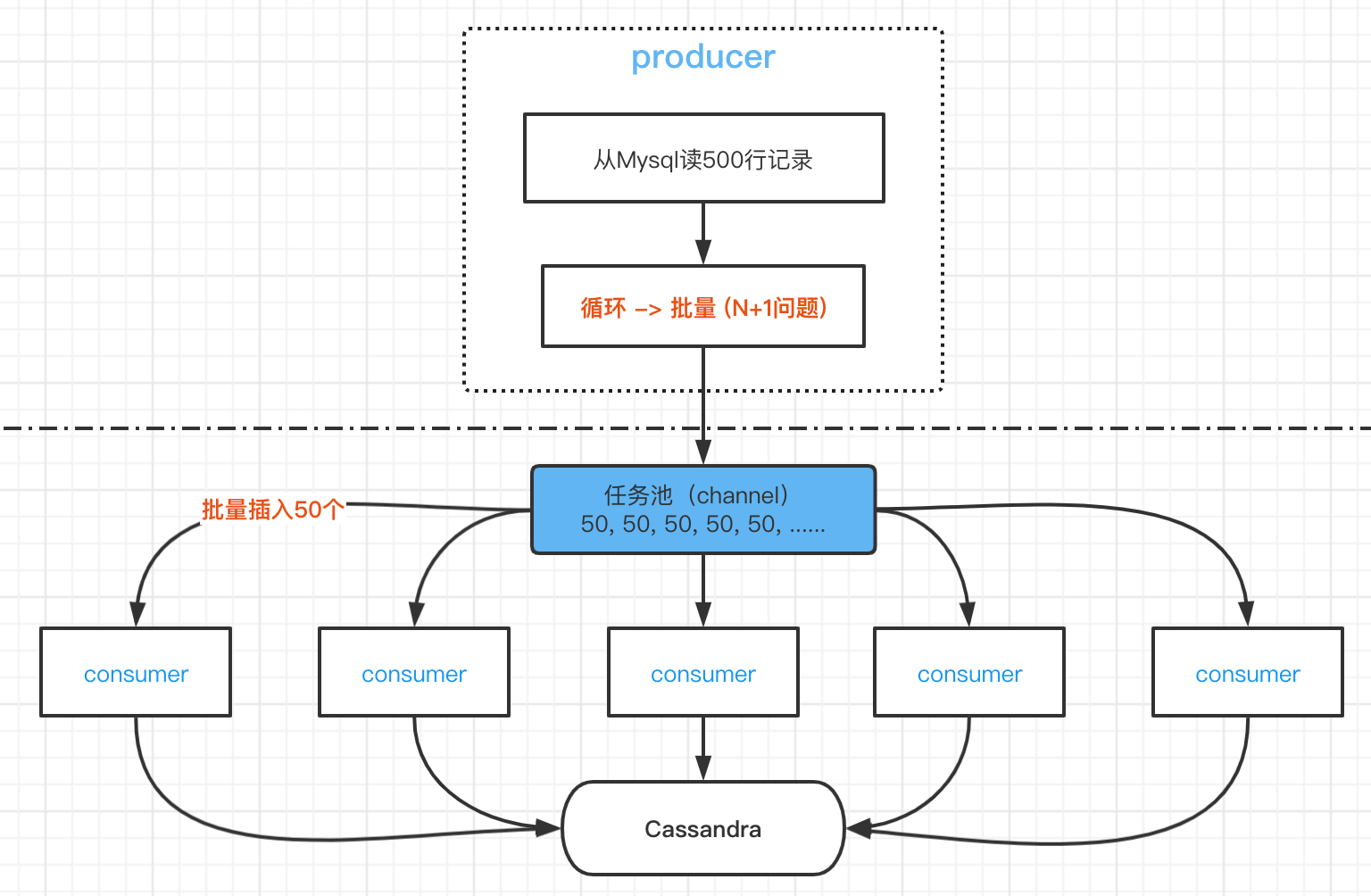
- 批量处理从Mysql读出的数据(相当于修复N+1问题)
- 批量写入 Cassandra
使用BATCH语句, 虽然 BATCH 不是设计来提升性能的,但是能减少 rtt,减少网络上的开销,而且读 Mysql 数据是通过企业 ID,同时企业 ID 也是我们 Cassandra 的 Partition Key,确保了一次 BATCH 写都在同一个 Partition 里。 但需要注意的是 BATCH 是原子的,上面提到的用了INSERT ... IF NOT EXISTS,一个已存在的数据就会导致所有插入失败,如果是这种情况就回退到一个一个的写入 (这里有一个小优化点:如果一条记录的 updated_at 大于了开启双写的时间,说明这条记录已经通过双写的方式写入 Cassandra 了,就可以过滤掉)。
这个方案,观测下来,写入效率快的能 1800/s,慢的 600/s,平均可能有个 1000/s 左右吧,算下来 7.5d 能同步完成。
v3
在方案 v2 上,做过一些额外的调优:
- 增加一次从 Mysql 去读数量 (500->1000->2000)
- 增加消费者数量 (5->8)
- 提高 BATCH 写入的数量 (50->100)
测试下来效果并不是很明显, 通过增加各步消耗时间的日志,发现时间主要卡在了读 Mysql 上,读取 1000 条数据大概在 0.3s,而把这些数据写入 Cassandra 不到 0.2s。 所以就想到提高生产者的数量,提高生产者的做法:每个生产者读不同企业 ID 的数据。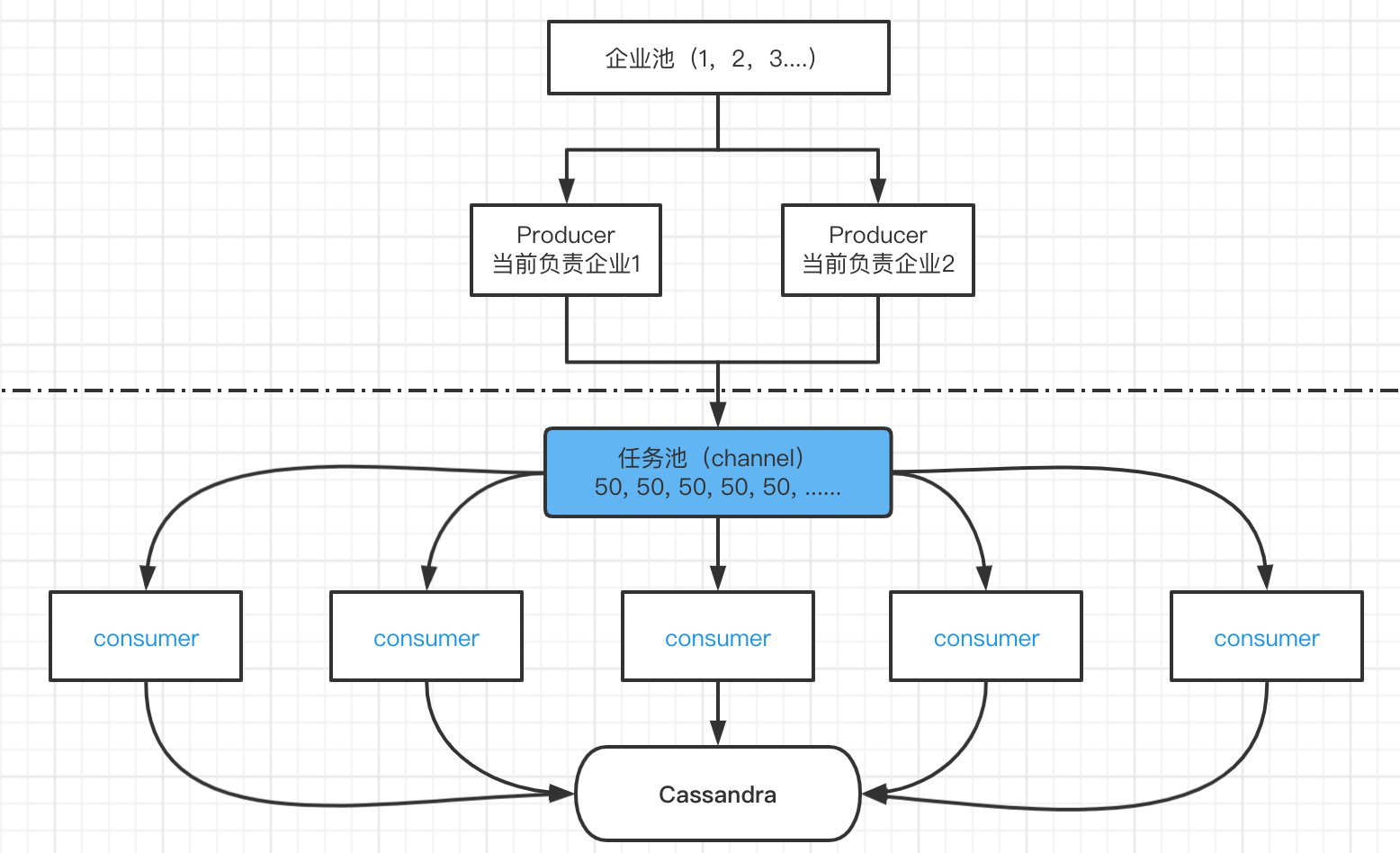
但之前提到过同步脚本是需要支持保存当前的同步进度的,方案 v2 判断当前进度的逻辑:存所有消费者最小的进度 (最小的进度之前的数据肯定已经迁移完成,宁愿重复跑一些数据,也不能漏掉一些数据)。 变成多个消费者就需要存下每个企业 ID 的进度,但判断一个企业 ID 的数据是否同步完成,似乎是一件很麻烦到的事情(只能通过判断写入Cassandra数等于从Mysql读入数)。
v4
v3方案保存当前同步进度之所以麻烦,是因为每个Consumer都能消费所有的Producer生产的数据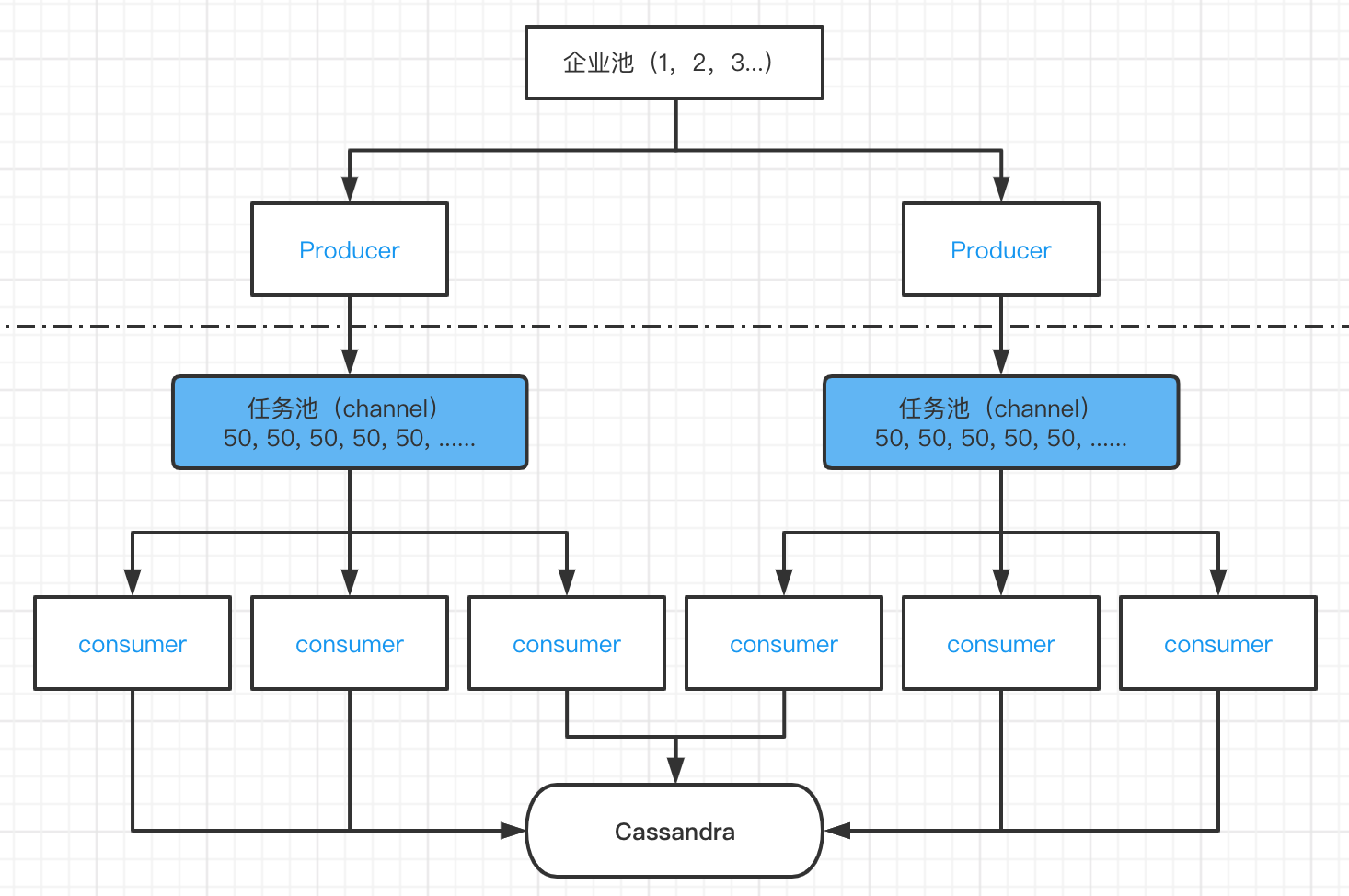
一个 Consumer只会消费一个 Producer的数据,这样当前进度的方案就跟v2一样了
v5
把 Producer 拆成2部分
- ProducerA: 负责从Mysql读取原始数据
- ProducerB:负责处理原始数据
流水线作业
其他坑点
迁移的第三步应该是要切换掉所有读的地方到 Cassandra,但由于某些原因,漏掉了一些。这部分有一些是读取数据写入 ES,导致 ES 又有问题,又得写脚本去修复 ES 数据