问题
systemctl reload caddy超时,systemctl reload默认最大时间是90s,说明reload超过了90秒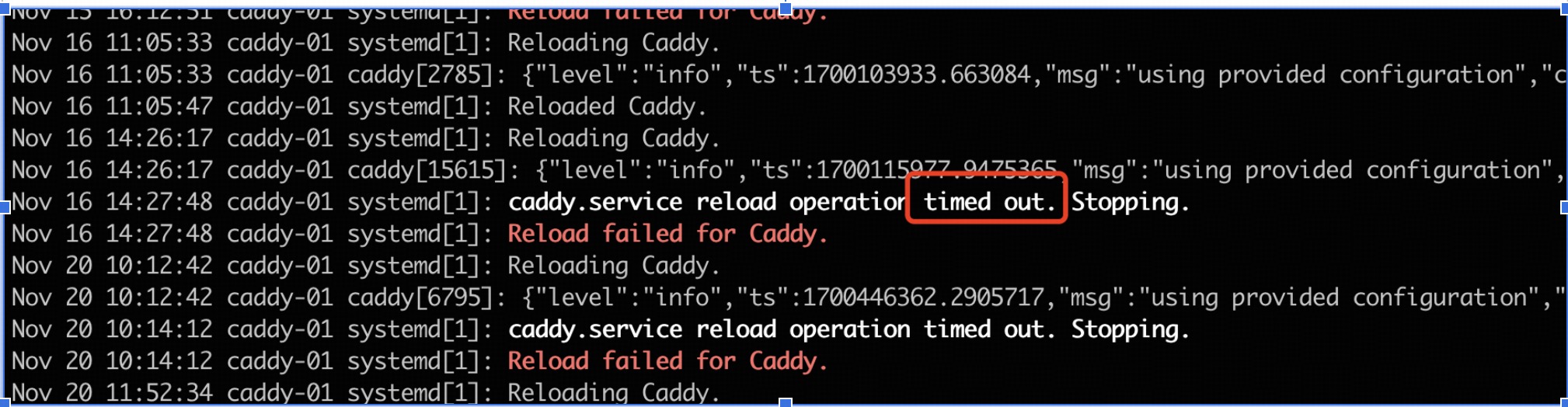
手动执行 caddy reload --config xxx
1700446704 - 1700446362 = 342s
定位
查看caddy reload的源码: https://github.com/caddyserver/caddy/tree/v2.4.6
- cmd/commands.go调用cmdReload,apiRequest 发请求/load
1
err = apiRequest(adminAddr, http.MethodPost, "/load", headers, bytes.NewReader(config))`
- 找到
/load路由定义的地方,caddyconfig/load.go#handleLoad 处理load请求1
2
3
4
5
6
7
8
9
10
11
12func (al adminLoad) Routes() []caddy.AdminRoute {
return []caddy.AdminRoute{
{
Pattern: "/load",
Handler: caddy.AdminHandlerFunc(al.handleLoad),
},
{
Pattern: "/adapt",
Handler: caddy.AdminHandlerFunc(al.handleAdapt),
},
}
} - handleLoad的核心逻辑
1
err = caddy.Load(body, forceReload)
- caddy.go#Load的核心方法
changeConfig1
err = changeConfig(http.MethodPost, "/"+rawConfigKey, cfgJSON, "", forceReload)
- changeConfig的处理过程
- unsyncedConfigAccess 解析新的配置,存入全局变量中
1
err := unsyncedConfigAccess(http.MethodGet, parts[0], nil, hash)
- unsyncedDecodeAndRun 应用新的配置
1
err = unsyncedDecodeAndRun(newCfg, true)
- run 用新的配置启动新的server
1
2// run the new config and start all its apps
ctx, err := run(newCfg, true)- replaceLocalAdminServer reload admin server
- Start 用新配置启动apps
1
2
3
4for name, a := range newCfg.apps {
err := a.Start()
...
}
- unsyncedStop 调用各个apps的Stop方法
1
2
3
4for name, a := range cfg.apps {
err := a.Stop()
...
}
- run 用新的配置启动新的server
- unsyncedConfigAccess 解析新的配置,存入全局变量中
caddy 默认的app逻辑在 modules/caddyhttp/app.go,因为问题是reload慢,猜测是Stop出了问题
Stop的逻辑就是调用golang http server的Shutdown方法
1 | for _, s := range app.servers { |
Shutdown的逻辑是不断的关闭空闲连接,直到所有连接都关闭,有任意活跃连接在,都会一直循序下去
1 | for { |
猜测就是这里卡住了,如何验证猜想呢?
查看caddy的log,筛选请求时长大于100s的请求,从11-13开始有很多100s+的请求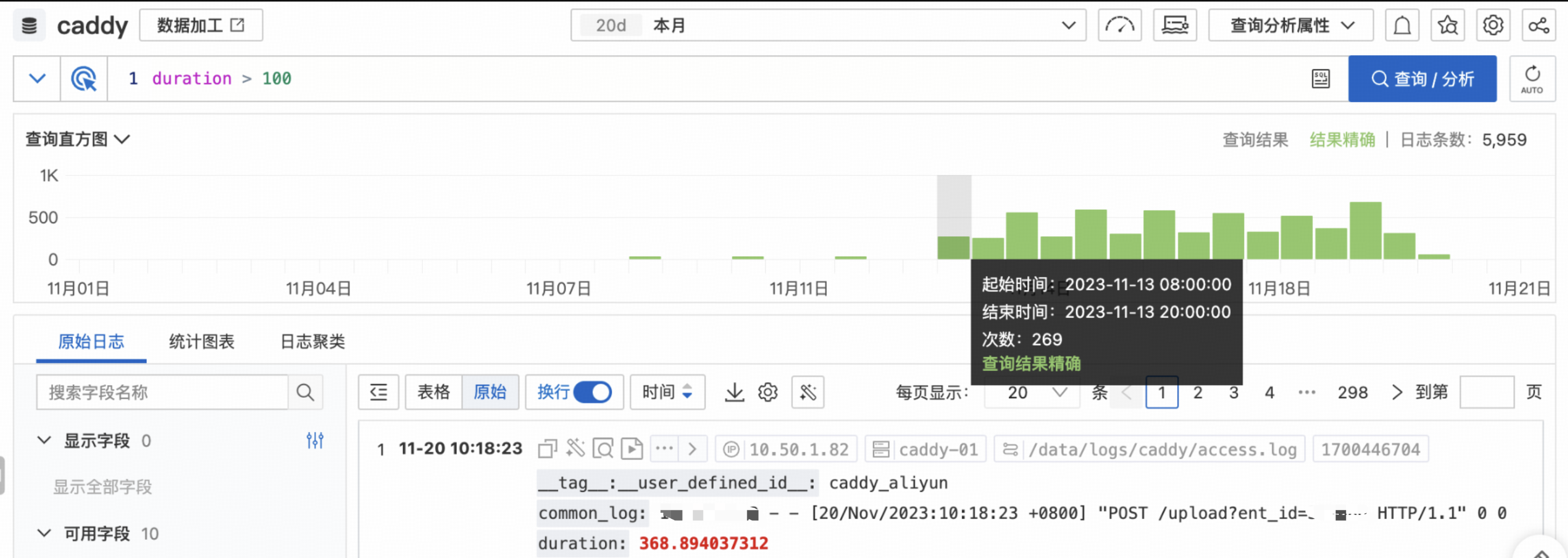
/upload是一个上传文件的接口,如果用户上传很大的文件或者用户的网络很慢,就会导致/upload请求很长时间
联想到公司最近做的架构调整,用阿里云的MSE网关替换掉了nginx,以前nginx是配置了client_body_timeout 10s,能保证用户最大上传时间为10s
而MSE网关只有一个这样的超时配置,看解释应该是upstream的timeout,对应nginx的proxy_read_timeout配置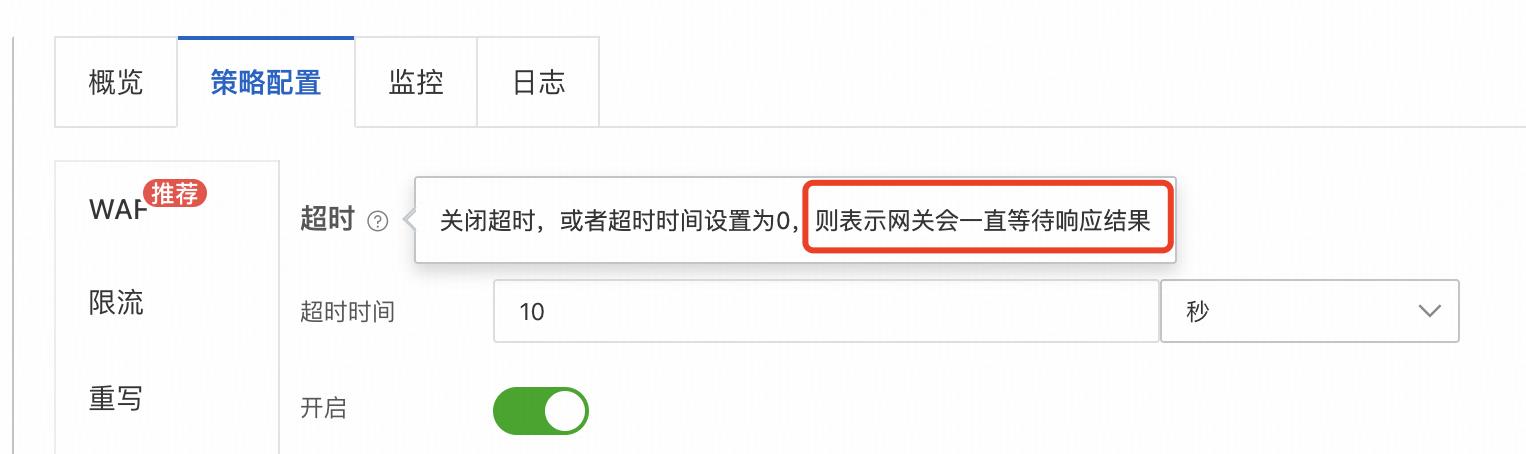
解决方案
因为mse不支持设置client_body_timeout,所以只能放到caddy的配置上处理
1 | servers { |